How Netflix’s MediaFM Understands Movies Using AI
Hello there, I love reading and learning in general.
But I know that a lot of people don’t.
Especially when the text is long and tech jargon-heavy.
But reading a company’s blog improves system design skills greatly.
I am starting a new series where I’ll provide simplified explanations of articles that I usually read.
Introducing CTRL+BREAK. Episode 1.
Today I’ll introduce you to this article that I recently read:
I’ll try to keep it small and simple yet comprehensive.

What Was The Problem?
What do you think is the best way to suggest a movie to someone?
I would say suggesting something I have already watched, based on that person’s interest, he/she would like it.
Now, Netflix very well knows what you like to watch.
But its recommendation system hasn’t seen the movie.
What I mean is that a movie, series, or documentary is not just its metadata.
It’s the audio that gets you immersed in it, the dialogue, and the visuals.
But we as humans see it all. How would an ML algorithm watch a movie?
Some Terms I Didn’t Know (Maybe You Don’t Either)
- BERT: A Transformer-based model that understands sequences (like sentences) using context.
- MSM (Masked Shot Modeling): Like fill-in-the-blank, but for videos.
- AdamW: A standard optimizer used to train deep learning models.
- Muon: A newer optimizer that Netflix found performs better for this model.
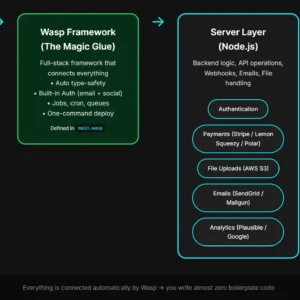
Why Multimodal + Core Architecture?
Because one type of data is not enough.
Example:
- A horror scene might look normal visually
- But scary because of the background music
So Netflix combines 3 things:
- Video → what’s happening
- Audio → how it feels
- Text → what’s being said
That’s the core of MediaFM.
What Do Shots (Input) Go Through?
Netflix refers to each movie or series episode as a title in this article.
Feeding a 2–3 hour title into a model isn’t a smart software decision.
That’s why the titles are broken down into shots.
A shot is a small segment of a title (between two cuts).
Here’s how the model works:
- Break title → into shots
- For each shot, extract:
- Video embedding
- Audio embedding
- Text embedding
- Combine them
- They create a single vector (2304 dimensions)
- Add sequence (VERY IMPORTANT)
- Shots are not random.
- They come in order: Shot1 → Shot2 → Shot3 → …
- Pass it through the Transformer like BERT, but for scenes.
- It understands:
- What came before
- What comes next
- How scenes connect
- It understands:
- Result:
- Each shot now has context-aware meaning
Why Have Embeddings As Result And Not Generation?
Do you know the concepts of reusability and DRY (Don’t Repeat Yourself)?
This is exactly the kind of problem they exist to solve.
If we directly generated text as the output, it wouldn’t integrate well with existing systems, and using its results as a common ground would be hard.
That’s why the results are in embeddings (like we keep API data in JSON so that it’s easy to be used by multiple systems)
How Did They Test It?
They first froze the model, meaning they didn’t fine-tune the MediaFM layer.
This allows them to create an additional layer based on the use case and then test the model.
Because if we need to refine this model again and again for various use cases, we would be violating basic efficiency principles and wasting compute, storage, and energy.
Then they tested this on various existing business use-cases.
They used proper evaluation metrics like:
- Average Precision (AP) → for classification (Are predictions correct?)
- Kendall’s Tau → for ranking (Are rankings aligned with real user behavior?)
They didn’t just test in isolation.
They compared MediaFM against:
- Internal model (SeqCLIP)
- External APIs (Google, TwelveLabs)
MediaFM performed better across all tasks
Ablation Study (Most Interesting Part)
This is where it gets really insightful.
What is ablation?
Remove one component and see what breaks.
They tested:
Case 1:
Only combine audio + video + text
(no context)
Case 2:
Add Transformer (context understanding)
Result:
- Just combining modalities → small improvement
- Adding context → huge improvement
The biggest improvement came from:
Understanding context (sequence), not just combining data
Final Thought
If I simplify this entire article into one line:
Netflix is building a system that watches movies like a human — but at massive scale.
Thanks for the explanation.