Day 2: Caching, CDNs, and Why JWT Tokens Aren’t Perfectly Safe
Today I dove deep into how to scale applications beyond basic server setups. Here’s what I learned:
Contents
1. Why Caching Matters
Going to the database repeatedly is slow and operations-heavy. Caching stores recent/frequent data in a faster layer (memory) so we don’t need database operations again and again. It’s most useful for read-heavy operations—that’s where you save the most performance.
Cache Considerations
Don’t store cache in a single place: A single cache server creates a single point of failure. Deploy multiple cache servers across data centers.
Optimal expiry time: Too short means constantly reloading from database; too long means serving stale data. Balance based on how frequently your data changes.
Eviction policies when cache is full:
- FIFO (First In First Out): Simplest—removes oldest entries
- LRU (Least Recently Used): Most popular—removes data not accessed recently
- LFU (Least Frequently Used): Removes data accessed least often overall
Read-through cache: Web server checks cache first—if data exists (cache hit), return immediately. If not (cache miss), query database, store result in cache, then return to client.
What are Memcached and Redis?
Memcached: Simple, fast, multithreaded caching for basic key-value storage (strings only). Best for straightforward caching with high throughput.
Redis: Advanced caching supporting complex data structures (lists, sets, hashes), data persistence, replication, and clustering. It can function as both a cache and a database. Redis is the recommended choice for most applications because it does everything Memcached does and more.
Note: Memcached has nothing to do with memset() in C/C++—different things entirely! (Just in case it confused you like me)
2. Content Delivery Network (CDN)
CDN is a layer that intercepts requests for static assets (images, videos, CSS, JS files) before they reach your web server. It’s typically a third-party service (Cloudflare, Amazon CloudFront, Akamai) unless you’re Google or Amazon building your own.
Users access assets through CDN URLs instead of your origin server. The CDN server closest to the user’s geographic location delivers content, dramatically reducing latency. Think Taylor Swift’s content cached on American CDN servers, Ukraine news on European servers.
Key Points:
- Costs money: CDN providers charge per data transfer, so only cache frequently accessed assets. Remove rarely-used files to save costs.
- TTL (Time-to-Live): Controls how long assets stay cached. Balance between freshness and database load.
CDN Failure Management
Remember Cloudflare outages breaking the internet?
Your application must detect CDN failures and automatically fall back to serving assets from origin servers.
Without a fallback, your website becomes unusable during CDN outages, even though your backend is fine. Never make CDN a single point of failure—always have a path back to the origin.
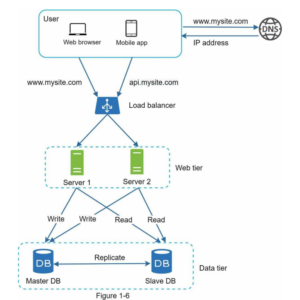
3. Stateless vs Stateful Architecture
The Problem: In stateful architecture, each user’s session ties to a specific server. Load balancer must use “sticky sessions” to always route User A to Server 1, User B to Server 2. This creates issues:
- Can’t scale easily—adding/removing servers disrupts sessions
- Poor load distribution—overloaded servers still must serve their users
- Server failure = lost sessions
The Solution: Move session data to shared storage (Redis, database) making every web server interchangeable. User A’s request can go to Server 1, next request to Server 3—doesn’t matter because all servers fetch session data from the same store. This enables true horizontal scaling, autoscaling, and better fault tolerance.
Firebase Auth and Clerk handle this beautifully by issuing JWT tokens—stateless by design.
4. JWT Tokens: How Authentication Works (My Curious Explore Not In The Book)
JWT (JSON Web Token) consists of three parts: header.payload.signature.
Header: Specifies token type and signing algorithm
Payload: Contains user data (user ID, email, expiration)
Signature: Cryptographic hash ensuring integrity
How It Works:
- User logs in with credentials
- Server verifies and generates JWT signed with secret key
- Client stores JWT (localStorage or HttpOnly cookies)
- Client includes JWT in Authorization header for subsequent requests
- Server validates signature—if valid, processes request
Why stateless: Server doesn’t store session data. All user info is encoded in the token itself, signed to prevent tampering. Server only needs mathematical signature verification—no database lookup.
JWT Security Concerns
My concern: If someone steals my JWT from cookies via a malicious link, they can impersonate me until the token expires.
- Store in HttpOnly cookies (JavaScript can’t access)
- Short expiration times (15-30 minutes)
- Refresh token rotation
- HTTPS only
- Device fingerprinting and IP validation
JWTs aren’t perfectly safe, but with proper measures, they balance security and scalability well.
5. Message Queues for Async Processing
Message queues enable asynchronous communication between web servers and worker servers. Here’s the flow:
- User uploads photo → Web server publishes job to message queue → Immediately responds “Job queued”
- Separate worker servers pull jobs from queue → Process photo asynchronously
- Workers complete task → Store result in database
Key benefit: Web servers and workers scale independently. Web servers don’t block waiting for slow tasks—they immediately serve more requests. If workers crash, jobs remain safely in queue.
Code-Level vs Architecture-Level Async
Code-level async (async/await in Python/Dart): Makes a single application responsive by not blocking on I/O operations. Flutter UI stays smooth while fetching data.
Architecture-level async (message queues): Decouples entirely separate systems across distributed infrastructure. Web servers and workers don’t even know about each other.
Both use “asynchronous” concepts, but at different scales.
6. Logging, Metrics, and Automation
What gets measured gets improved.
Logging
Centralized logging (ELK Stack, Splunk, Datadog) aggregates logs from all servers into one searchable interface. When something breaks, quickly search across all servers for root cause.
Metrics
- Host-level: CPU, memory, disk I/O per server
- Aggregated-level: Database tier performance, cache hit rates
- Business metrics: Daily active users, retention, revenue
Automation
[Example] CI/CD automates: Code pushed → Tests run → Deploy to all servers if tests pass. Eliminates error-prone manual deployments.
7. Database Sharding vs Replication
One-liner summary: Replication distributes operations. Sharding distributes data.
Replication: Copies the same data to multiple servers. Improves read performance and redundancy, but doesn’t help when data becomes too large.
Sharding: Splits different data across servers. Each shard holds a unique subset of data. Solves the problem when the database is too large for one server.
Use both together: Shard your data based on user_id, then replicate each shard with a master-slave setup. Shard 0 has its own master + slaves, Shard 1 has its own, etc.
Final Diagram In The Book After Chapter 1 Applied
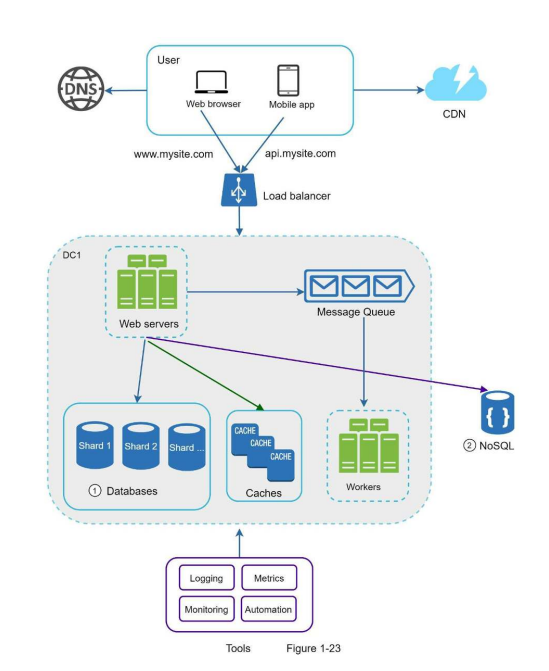
Image Credit: Book System Design Interview by Alex Xu
Next Steps
Chapter 1 complete!
I’ll read all the references provided tomorrow, or better, I’ll cut short and move on to developing the first version of my application, HunkIt, tomorrow itself.
I’ll go through references as and when needed.