Scrapped
After yesterday, my today’s goal was very simple. I wanted to create a simple working scraper that gets the data from web pages.
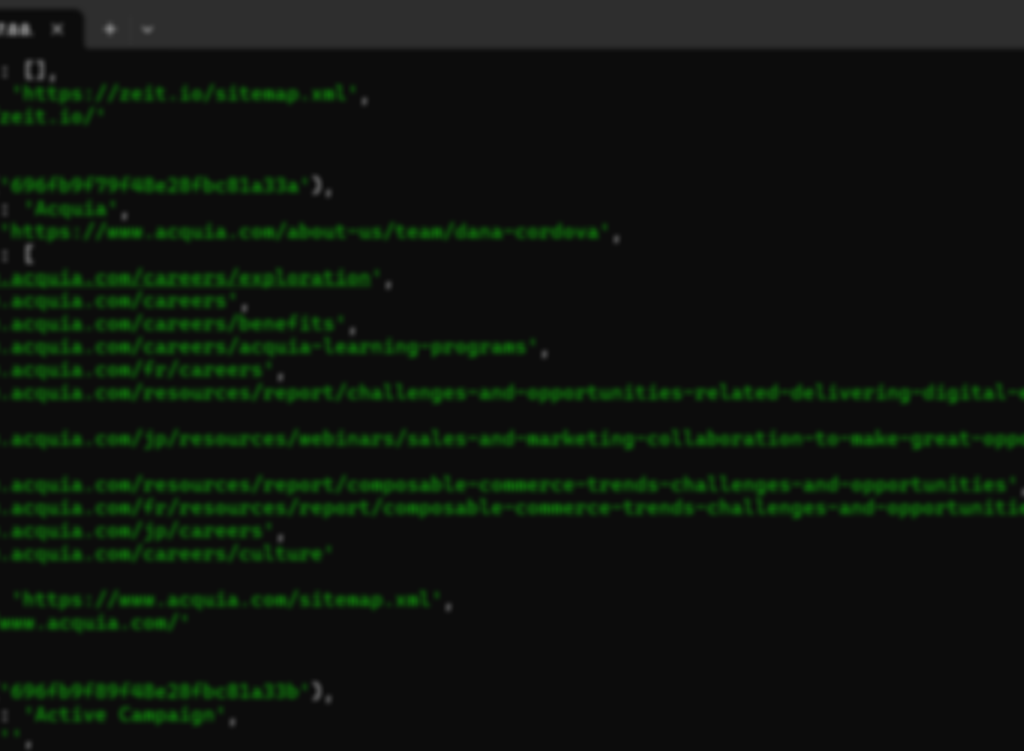
Today’s target: From Sitemaps, get career and about pages (links) and store them in the DB.
That’s it.
Instead of struggling with top companies whose details are available everywhere. I thought of starting out with startups on my list.
So, I got 35 from my list of companies and easily got their sitemaps.
Scrapped
The Strategy
- CSV Parsing: Some (3-4) companies didn’t have sitemaps so I had to have direct links for them.
- Sitemap Filtering: Instead of saving all URLs, I need to store only the career and about pages URLs. (We would need about page when writing emails)
- MongoDB Integration: Store data in this structure inside mongoDB:
- “Company Name”: { “URL”: site_url, “Sitemap URL”: sitemap_url, “Career Pages”: [career_pages], “About Page”: about_page }
I later added docstrings and type hints with the help of AI.
The code is updated on GitHub: https://github.com/maitry4/HuntKit
Today was easier. I learnt works first scales next builds scalable systems faster.
A blurry sneak peek of my database: